Today at 6:30 PM I had to say goodbye, but you will forever stay my little girl
23 Apr 2026 • < 1 min. read

Well, me and my awesome colleagues (yes, they sometimes check this blog) have been migrating away from big-tech like Microsoft, Google, Oracle, Apple etc. Not because they were no good (most of our core is still running on AWS servers) but because we became sick of the AI-slop and data-sucking most are nowadays involved in. Anyways, we also decided to do a bit of self-hosting and move all our laptops to something different. No more Ubuntu or Fedora but suckless DWM on Arch (with the LTS & performance kernels).
Migrating was tough, writing a bunch of add-ons even harder, but the final result is here to stay. On a personal note on my 2 systems I additionally:
I didn’t look for the lighter tools, but for ones I could trust and reason about. Less abstraction, fewer surprises.
Today I use two identical laptops – one for work, one personal – same setup, side by side, one mouse for each. The environment disappears, and the work stays.
And for what its worth, the DWM I’m sporting now is one that no one else has; it is mine and in that sense truly unique. You build your own program, patches, the binds et al.
Making sure all prerequisites are fulfilled you can then just copy your suckless configs to basically any distro and run a sudo make clean install.
I guess I finally found my sweet spot after all.
All you need to know when examining your Linux server system.
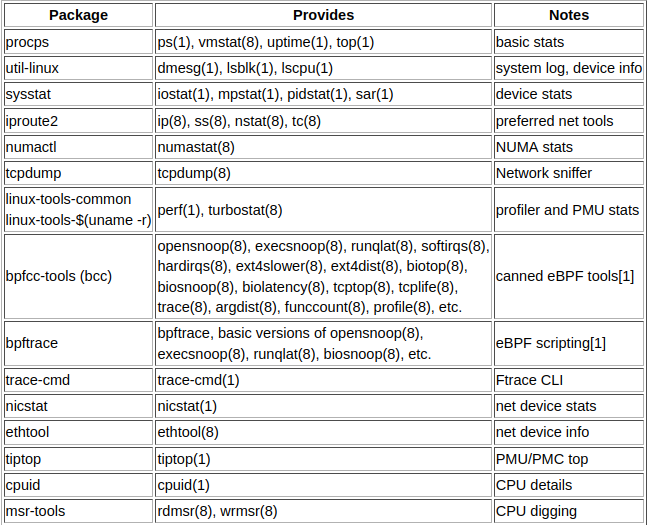
Be sure to check out Brendans blog for a galore of other diagrams and books!
Since I was talking about Vim, the Acme Text Editor written by Rob Pike for Plan 9 in the early 1990s is another favorite. Nothing but yellowish windows and blue bars with a focus on the job to be done.
Acme combines several aspects of window systems, shells, and editors. Designed to support software development but not a true programming toolkit. Instead, it is a self-contained program; more like a shell than a library, that joins users and applications.
From the perspective of the application e.g. compiler, browser, etc., it provides a universal communication mechanism based on familiar Unix or GNU - Linux file operations, that permits your small applications even shell procedures to exploit the graphical user interface of the system and communicate with each other.
For the user, the interface is extremely spare, consisting only of text, scroll bars, one simple kind of window, and a unique function for each mouse button. There are no widgets, no icons, not even pop-up menus.
Despite these GUI limitations, Acme is still an effective environment in which to work and, particularly, to program.
It’s rather difficult to explain how it works without seeing it though, so I added a screencast from Russ Cox’s Golang page showing a brief programming session.
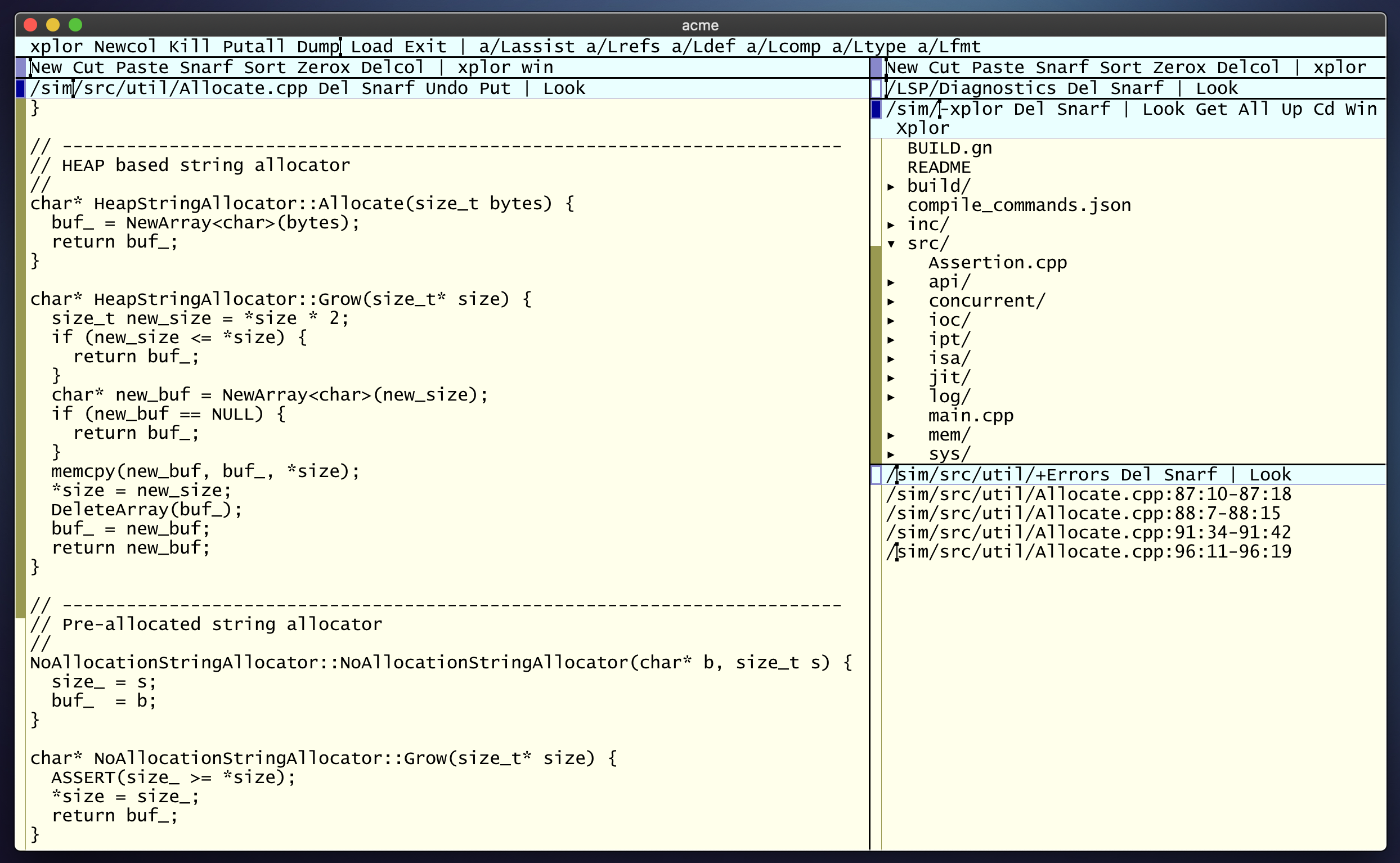
PS. Each time people tell me today’s Acme users are borderline insane, I send them the above link and they usally shut up.
For the past three years I used Vim almost exclusively to become efficient with it.
I wrote code, countless articles and documentation. Me and Vim we were ok till I watched this video and realized I had been living in blissful ignorance, relying on plugins, a 200 lines long .vimrc file that completely changes how Vim works, and bad advise given by people who know nothing about VI.

Please note that Chris Toomey is ‘flying’ through commands and concepts, which makes it quite difficult to follow for Vim newbs and regular users alike.
Can’t believe I’ve never mentioned Goyo, one of my most used Vim plugins ever.
It adds a distraction free mode that helps me focus while writing by centering the content and hiding all other elements.
Other nice features are the support of console ANSI-sequences for curl, httpie or wget; HTML for web browsers; or PNG for graphical viewers.
Toggle Goyo:
:Goyo
Turn on and resize Goyo to the dimension 100x50:
:Goyo 100x50
Turn off Goyo:
:Goyo!
The plugin works just fine as is, but I did change the text area in my vimrc config file (as seen in the image above), as I find that to be a better fit for my eyes:
let g:goyo_width=100
let g:goyo_height=50
Finally, as piece de resistance, I added a shortcut by bounding the toggle feature to the key g:
map <C-g> :Goyo<CR>
Are you interested in trying Vim? I can highly recommend checking out this link. Trust me, it’s by far not that hard as many people want you to believe. :)